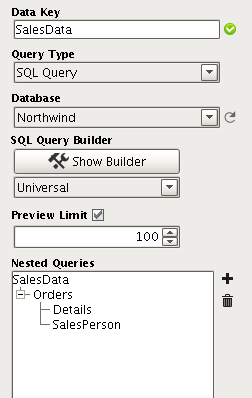
Nested Queries
Query Nesting turns complex data relationships into easily reportable structures and will undoubtedly be one of the most useful Reporting v3 features for. So what is a Nested Data Source? The simple definition is that a Nested Query uses the results of a previously executed query to collect data. The general structure of a Nested Data Source is one in which you have a Parent queries and child queries. Those well-versed in SQL are probably thinking that this sounds like a JOIN and in fact, there are some similarities. There are also some major differences which allow Nested Data to be both easier and more powerful to accomplish:
-
Nesting relationships are not restricted to data in a single schema, database or even source! Nesting is easy to configure across tables, between different databases, or even with sources like the Tag Historian!
-
Writing queries for nested query sources can be far simpler and easier to maintain than writing complex JOIN operations
-
Nested structures allow more control in how data is collected, allowing data structures and relationships that are more expressive
How Nesting Works
Let's use a simple data relationship to help illustrate how nesting occurs.
Imagine we have data collected from two unrelated sources that look the ones seen in this table.
|
Codes |
Frequency |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
We want to create a data source connecting all these things for reporting using nesting. The process to accomplish this is:
-
Create a new data source to be the Parent query. The parent query will likely depend on what your data looks like. For this example, we'll just use the Codes data.
-
Give your data source a meaningful name, CodeFrequency will work for us.
-
Create a Child Query by clicking the
 button in right configuration pane of your data source, also giving it a name. We will call this nested data NEST.
button in right configuration pane of your data source, also giving it a name. We will call this nested data NEST. -
In the Child query, reference one or more column values from the parent.
Example of what these queries could look like:
-- Parent Query SELECT * FROM Codes -- In the Child Query, accessed by clicking on the NEST leaf of the Nested Queries Tree-- This assumes the value of Parameter 1 would be equal to {CodePK}SELECT FrequencyID, Frequency FROM Frequency WHERE CodeID = ? 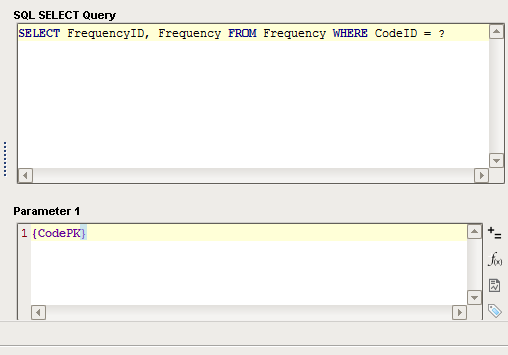
How Nesting Works
With this simple example, what happens is that first the parent query is called, and a set of results is returned to the reporting system with the name of our parent CodeFrequency . Only after this data has returned, the Child query will execute, once for each row of the parent, substituting the value of CodePK into the child query where we have the {CodePK} reference.
The resulting first two rows of data will have a structure like this:
CodeFrequency | |-Row 1 | |_ CodePK - 1 | |_ Code - ZG | |_ NEST | |_ FrequencyID - 1 | |_ Frequency - 11 | |-Row 2 | |_ CodePK - 2 | |_ Code - GB | |_ NEST | |_ FrequencyID - 6 | |_ Frequency - 32 Each row returns the CodePK and Code from the parent query, but also the results of the child query, that apply to the CodeID we get from the parent PK.
It may be easier to see the data returned in a flatter form like a table that relates the values by row, ignoring the tree structure:
|
Parent Query Row |
CodePK |
Code |
FrequencyID |
Frequency |
|
1 |
1 |
ZG |
1 |
11 |
|
2 |
2 |
GB |
6 |
32 |
Now, in our Report Design, we will have access to our datasource FrequencyData that has linked these two sets of data together through a shared value.
Special Considerations
Nested Queries are powerful and easy to use, but users should be aware of runtime implications. Imagine the scenario above, where we have two sets of data, each with 5000+ rows. When our child query executes, each row of its query is going to require a lookup from the parent. For most common sets of data and database sizes, this won't be an issue, but it's possible to imagine that instead of just one child query, we have a dozen. In addition, some of those children also have many children. It's very easy to see in this scenario how exponential growth occurs and our system performance may suffer. Most report designers will limit query sizing as oversized data structures are simply not as easy to work with. However, if you feel an urge to generate massive complex trees of million line queries, you may be waiting a while.